SpringBoot 热部署
概述
最近由于团队缺人,做了一个前后端不分离的web项目。因为看过那本《JavaEE开发的颠覆者: Spring Boot实战》,之前在当当也写过一些前端代码,所以理所当然的选了AngularJs1 + BootStrap + SpringBoot作为技术栈来完成任务。说实在的,SpringBoot基本的功能,书里写的还是挺详细的,只是AngularJs和BootStrap如果没有人指导一下,上手还是挺困难的。说起这事儿,还要感谢当时在当当的时候那个带我的小师父。有问必答不厌其烦,且能引导人思考,挺好的人。
写前端代码的时候,有时候想立刻得到调整后的结果,如果仅仅是样式,可以通过浏览器控制台调试。但是涉及到js脚本,除了热部署我还真没想到其他更好的方式,搜了很多网页,最后记录一下亲测好用的方法。
步骤
1 导包
<!--SpringBoot热部署配置 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-devtools</artifactId>
<scope>runtime</scope>
<optional>true</optional>
<version>2.4.5</version>
</dependency>
2 配置项
在配置项中增加这一行:spring.devtools.restart.enabled=true
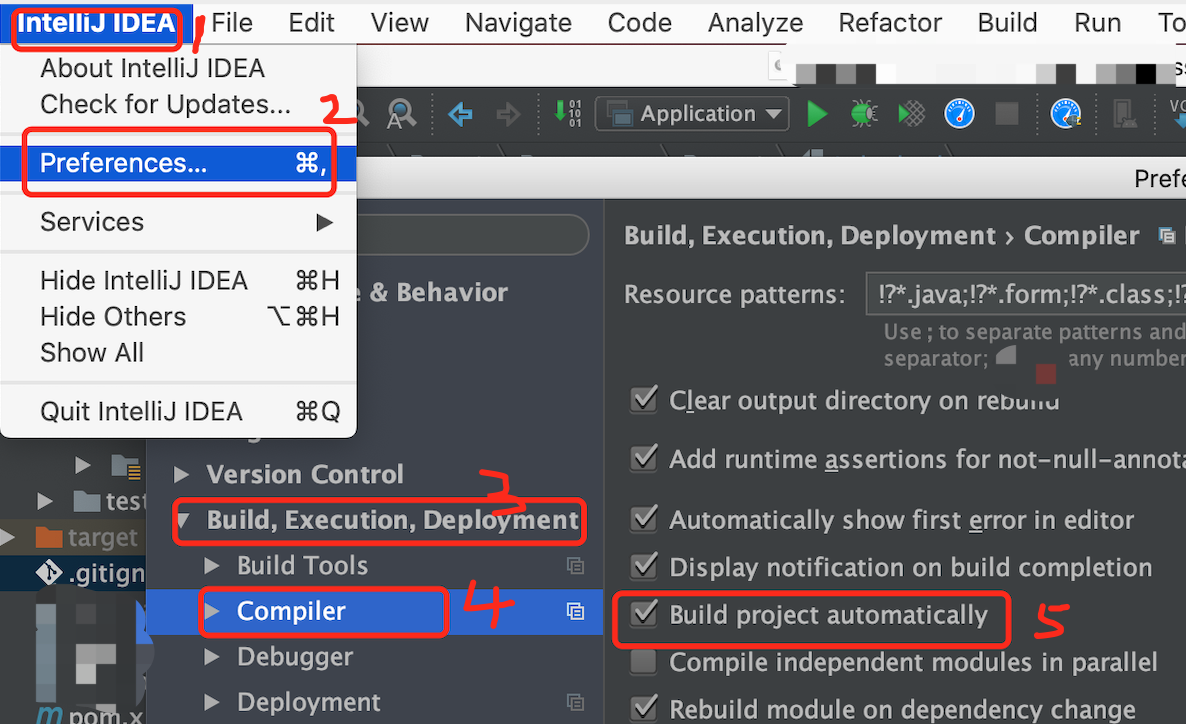
3 IDEA配置
3.1 第一处修改
在这个路径下:Preferences -> Build, Execution, Deployment -> Complier,找到Build project automatically,选中。例子图示如下:
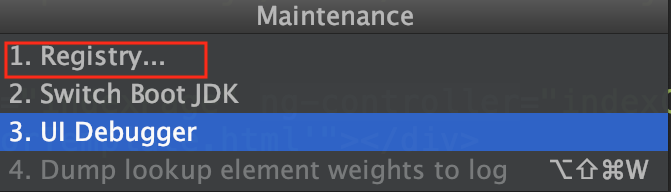
3.2 第二处修改
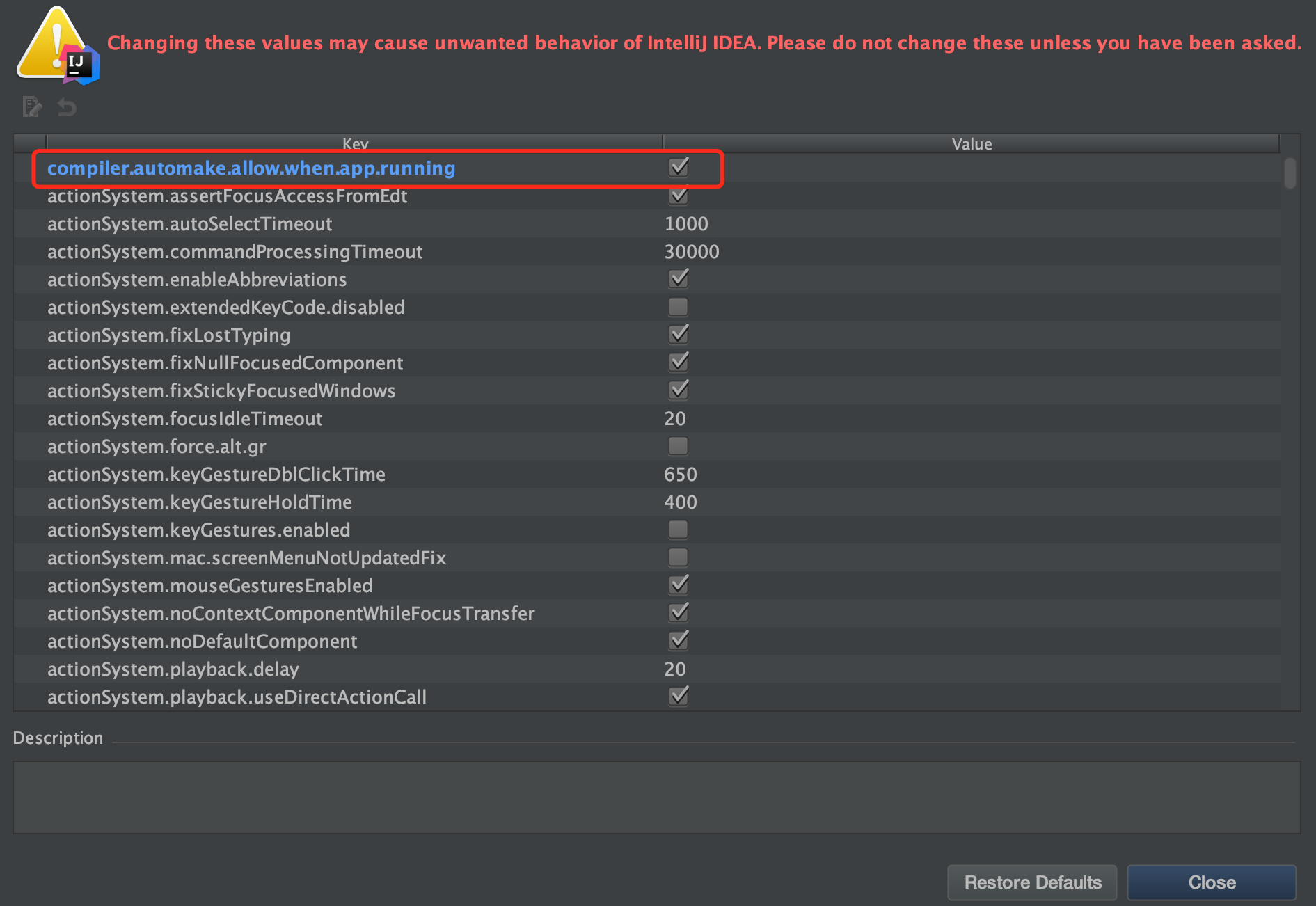
Mac系统使用组合键:shift + option + command + /,弹窗中单击Registry,新弹窗勾选compiler.automake.allow.when.app.running
redis学习
概述
redis在大部分时候,被用作缓存,用于加快查询速度。但其适用范围,不仅仅限于缓存,比如用户关系的存储:求两个用户的共同关注好友。就可以使用redis的列表类型求交集来完成,操作简单、高效。 之前看过一本《redis开发与运维》,里面讲的是如何使用redis,对于redis如何管理(运维)。对于没接触过redis的人,可以通过那本书入门上手。最近在看《redis设计与实现》,这本书里讲的是原理层面的内容,适用于充分理解其解决问题的思路。 我希望通过这篇总结,可以讲清楚,为啥redis这么快,如何实现的。
字符串
redis是用C语言实现的,其基本的5中数据结构中,字符串是最简单的。后续支持的地理位置,出了LBS相关业务,其他的基本用不上。 KV结构中,字符串这种数据结构,redis依托于C语言,有自己的实现:简单动态字符串(simple dynamic string SDS),其数据结构有三个元素:len(字符串长度),free(未使用空间),buf(实际字符数组)。
buf数组,实现仍然是参考C语言,这样可以使用一部分C语言的字符串库函数。也就是说:以\0表示字符串结尾。但是len统计长度的时候,是不包含\0这一字节的。
SDS解决了C语言字符串的两个问题:1 获取字符串长度代价高;2 无法自动扩展;3 无法保存带有\0格式的二进制数据
优势1:获取字符串长度的时候,仅仅访问其len属性即可得到。而C语言的字符串需要遍历,才能获取到。
优势2:防止出现缓冲区溢出。C语言字符串在执行
优势3:可以保存任意格式的二进制数据,而非仅仅文本数据。(就算数据有\0也能保存)
分配空间的时候,使用“预分配”和“惰性释放”两个策略,减少分配内存操作次数,降低耗时。
链表
链表的底层实现用的是
字典
字典的底层实现用的是
spring的拦截器和过滤器
概述
spring有拦截器有过滤器,对其过滤路径和场景做说明。
过滤器
implements javax.servlet.Filter,然后实现其方法就写好一个过滤器了。注入bean的方式,添加过滤器代码如下。过滤器属于servlet规范,基于函数回调实现,所有请求都可以拦截,比如静态资源图片、jsp、js等。其实现代码如下
@Bean
public FilterRegistrationBean crossDomainFilter() {
FilterRegistrationBean crossDomain = new FilterRegistrationBean();
crossDomain.setFilter(new CrossDomainFilter());
crossDomain.setName("cross-domain-filter");
crossDomain.setOrder(0);
crossDomain.setUrlPatterns(ImmutableList.of("/*"));
return crossDomain;
}
上述代码中,setUrlPatterns参数可以是个正则路径,这里使用/*拦截所有请求,使用/api/*拦截api开头的请求。
拦截器
implements org.springframework.web.servlet.HandlerInterceptor,然后重写各方法。拦截器属于spring规范,基于反射实现,只拦截请求,比如静态资源图片、js等不会拦截。拦截器定义的代码如下
public class LogInterceptor implements HandlerInterceptor {
private static final Logger LOGGER = LoggerFactory.getLogger(LogInterceptor.class);
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
LOGGER.info("LogInterceptor preHandle");
return true;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, @Nullable ModelAndView modelAndView) throws Exception {
LOGGER.info("LogInterceptor postHandle");
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, @Nullable Exception ex) throws Exception {
LOGGER.info("LogInterceptor afterCompletion");
}
}
拦截器使用的代码
@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})
public class WebsiteApplication implements WebMvcConfigurer {
public static void main(String[] args) {
SpringApplication.run(WebsiteApplication.class, args);
}
@Override
public void addInterceptors(InterceptorRegistry registry) {
// 拦截器有序 ArrayList
registry.addInterceptor(new LogInterceptor()).addPathPatterns("/**");
registry.addInterceptor(new UploadSqlInterceptor()).addPathPatterns("/api/**");
}
}
拦截路径
addPathPatterns和excludePathPatterns
如果二者都存在,则优先判断exclude,再经过include。其拦截方式源码在拦截器的代码在org.springframework.web.servlet.handler.MappedInterceptor类的matches方法。
拦截器的拦截路径匹配关系与过滤器不同,
/*和/abd/*表示只拦截该匹配路径。比如/ab、/abd/a,不能拦截/abd/a/b
/**和/abd/**表示拦截匹配路径 及其子路径。比如/abd/a/b
拦截器使用方式
如果想让一个拦截器拦截两个路径,用过只调用一次addInterceptor,并一次性写完拦截路径。如果写两个addInterceptor语句,则容易达不到预期。例子如下。
// 1. 意思是:不能拦截api/v3和api/v4开头的接口。
registry.addInterceptor(loggerInterceptor).excludePathPatterns("/api/v3/**", "/api/v4/**");
// 2. 前一句意思是不能拦截api/v3开头的接口,但是可以拦截api/v1、api/v2、api/v4等开头的接口。
// 后一句意思是不能拦截api/v4开头的接口,但是可以拦截api/v1、api/v2、api/v3开头的接口。
// 所以,以下两行代码加起来的意思是,所有接口都能被拦截,且/api/v2/开头的,要以语句定义顺序,被拦截两遍。
registry.addInterceptor(loggerInterceptor).excludePathPatterns("/api/v3/**");
registry.addInterceptor(loggerInterceptor).excludePathPatterns("/api/v4/**");
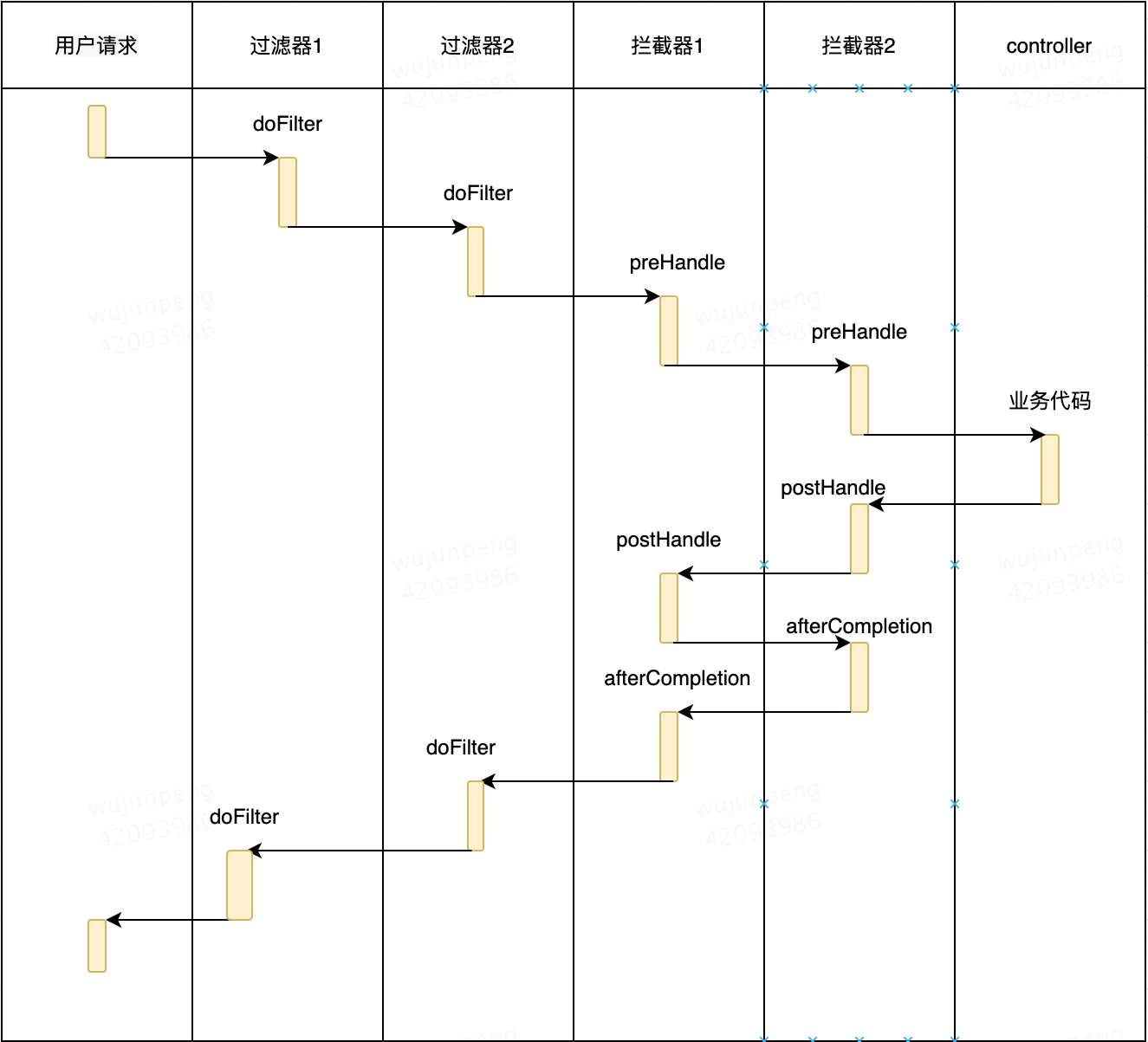
过滤器和拦截器调用顺序
虚拟机启动时,过滤器初始化方法init调用顺序未知;同理,虚拟机关闭是,过滤器销毁方法destroy调用顺序未知;
接受用户请求时,过滤器和拦截器的调用顺序
shell相关
概述
#!/bin/bash
# 告诉系统这个脚本需要什么解释器来执行,即使用哪一种 Shell。
:<<!
多行注释...
多行注释...
多行注释...
!
字符串
echo "hi, jiler."
echo "hi, wujunpeng"
# 变量名和等号之间不能有空格
myName="wujunpeng"
echo $myName
echo ${myName}
# 只读变量
readonly myName
# 删除变量(不能删除只读变量)
unset myName
# 字符串长度,效果一样
str="test str"
echo $#str ${#str}
# 截取字符串,从第2位开始,截取1个字符
echo ${str:1:1}
获取参数
# 比如命令行执行为文件 ./start.sh
./start.sh wujunpeng firstPlan
# 在./start.sh内部获取参数时,
echo "执行的文件名:$0";
echo "第一个参数为:$1";
echo "第二个参数为:$2";
# $10 不能获取第十个参数,获取第十个参数需要${10}
$# # 表示参数个数
数组
int_arr=(1 2 3 4 5)
str_arr[0]=My # #!/usr/bin/env zsh 数组下标从1开始
str_arr[1]=name
str_arr[2]=is
str_arr[3]=wujunpeng
echo $int_arr[1]
echo "数组的元素为: ${int_arr[*]}"
echo "数组的元素为: ${int_arr[@]}"
length=${#int_arr[*]} 获取数组长度
length=${#int_arr[@]} 获取数组长度
置换
# 变量置换
word=replace
echo ${param}
echo ${param:-${word}} # 如果param为空 或 未赋值,用word的内容取代param,但param不变
echo ${param:=word} # 如果param为空 或 未赋值,用word赋值给param
echo ${param:+word} # 如果param有值,用word取代param,但param不变
# 命令置换
DATE=`date`
echo ${DATE}
# 算式置换
echo $((1+2))
if条件
a=10
b=20
if [ $a == $b ]
then
echo "a 等于 b"
fi
if [ $a != $b ]
then
echo "a 不等于 b"
fi
# 写成一行
if [ $a == $b ]; then echo "a 等于 b"; fi
# if后的可以使用其他的语法,判断数据是否相等
if [ $a -eq $b ] # 判断相等equals
if [ $a -ne $b ] # 判断不相等 not equals
if [ $a -gt $b ] # 判断> greater than
if [ $a -lt $b ] # 判断< less than
if [ $a -ge $b ] # 判断>= greater or equals
if [ $a -le $b ] # 判断<= less or equals
# 与或非 -a -o !,直接用&& 和 || 也支持
[ $a -lt 20 -a $b -gt 100 ] # if (a < 20 && b > 100)
[ $a -lt 20 -o $b -gt 100 ] # if (a < 20 || b > 100)
# 可以判断字符串是否为空
if [ -z $str ] # 检查字符串长度是否为0,如果为0则返回true
if [ -n $str ] # 检查字符串长度是否不为0,如果不为0则返回true
if [ $str ] # 字符串为空返回true
# 可以判断文件类型
if [ -f $fileAddress ] # 如果是普通文件(不是目录,不是设备文件)返回true
if [ -r $fileAddress ] # 检查文件是否可读;如果检查可写用-w,可执行用-x
if [ -e $fileAddress ] # 检查文件是否存在,存在返回true
test
if test -e $str # 如果文件存在
循环
for
for each in 1 2 3 4 5
do
echo $each
done
# for循环遍历数组
int_arr=(1 2 3 4 5)
for each in ${int_arr[@]}
do
echo $each
done
# for循环遍历带空格的元素
name_arr[0]=jiler
name_arr[1]="jiler hell"
SAVEIFS=$IFS
IFS=$(echo -en "\n\b")
for each in ${name_arr[@]}
do
echo ${each}
done
IFS=$SAVEIFS
until
a=0
until [ ! $a -lt 10 ]
do
echo $a
a=`expr $a + 1`
done
case switch
case $aNum in
1) echo '你选择了 1'
;;
2) echo '你选择了 2'
;;
3) echo '你选择了 3'
;;
4) echo '你选择了 4'
;;
*) echo '你没有输入 1 到 4 之间的数字'
;;
esac
seq序列遍历
基本语法:
1 seq [选项]… 尾数
2 seq [选项]… 首数 尾数
3 seq [选项]… 首数 增量 尾数
seq -s '#' 5 # 指定分隔符,横向输出 1#2#3#4#5
seq -s ' ' 10 # 空格作为分隔符
seq -w 1 10 # 前面补0,输出1-10
seq 1 2 10 # 从1开始,增量为2,不超过10
seq -f "%03g" 98 101 # 宽度为3,不足补0
重定向
# 输出 重定向 到test.sh文件
echo "wujunpeng" > test.sh
# 输入 重定向 到test.sh文件
command < test.sh
# 重定向输出,追加
echo "wujunpeng" >> test.sh
# 重定向输入
file < test.sh
# 将标准输出和标准错误输出 以追加的方式 重定向 到文件file
command >> file 2>&1
文件包含
# 类似于include import等,可通过两种方式
source ./test1.sh
. ./test1.sh
awk 命令 行处理
处理文本文件的语言,是一个强大的文本分析工具
awk '{print $1,$4}' log.txt # 打印出 log.txt文件 每行按空格分隔的第一个和第四个元素
awk -F, '{print $1,$2}' log.txt # 打印出 log.txt文件 每行按逗号分隔的第一个和第四个元素
awk -F '[ ,]' '{print $1,$2,$5}' log.txt # 打印出 log.txt文件 每行按先按空格,再按逗号分隔的第一个和第四个元素
awk -va=1 '{print $1,$1+a}' log.txt # 设置变量a=1,如果$1是数字,则是加法;如果$1是字符串,则连接
awk '$2 ~ /th/ {print $2,$4}' log.txt # 第二列包含th的行,打印出第二例和第四列,~表示正则匹配
awk '/re/ ' log.txt # 输出包含re的行
awk '$2 !~ /th/ ' log.txt # 输出第二列不包含th的行
awk '!/re/ ' log.txt # 输出不包含re的行
awk -f cal.awk score.txt # cal.awk内容详见附录
sed 命令
用脚本来处理文本文件,用来自动编辑一个或多个文件、简化对文件的反复操作、编写转换程序等。具体就不写例子了,目前其应用场景未知。
简单应用
# bc 命令
echo 'scale=2; (2.777 - 1.4744)/1' | bc # 保留两位小数进行计算
echo "obase=2;8" | bc # 十进制转二进制
echo "ibase=2;111" | bc # 二进制转十进制
echo "obase=10;ibase=2;1101" | bc # 二进制转十进制
echo "sqrt(100)" | bc # 开平方
# nohup 命令 后台运行,比如java的发布就可以用
nohup java -jar *.jar
# wc 命令
wc -l Hello.java # 统计文件中的行数 -w表示字数 -c表示字节数
# scp 命令
scp /user/wujunpeng/web/test.java wujunpeng@192.168.0.23:~/Desktop
# 如果是复制目录则用-r (-C 表示允许压缩 -P 4588表示指定端口)
scp -r /user/wujunpeng/web/test wujunpeng@192.168.0.23:~/Desktop
# xargs 命令 给命令传递参数的过滤器,也是组合多个命令的工具
seq -f "dir%03g" 1 3 | xargs mkdir # 联系创建多个目录
# curl http命令行工具
curl -o /dev/null -s -w %{http_code} https://www.baidu.com # 获取访问百度的返回值
# ps 命令
ps -ef | grep java
# 用mac电脑给手机充电的时候,有时候会出现频繁断开又链接的情况,用下面这个命令可以解决这个问题
sudo killall -STOP -c usbd
# nslookup 查询机器对应的域名
nslookup 10.3.43.4
# 端口被占用
lsof -i :8080
附录
awk文件内容
#!/bin/awk -f
#运行前
BEGIN {
math = 0
english = 0
computer = 0
printf "NAME NO. MATH ENGLISH COMPUTER TOTAL\n"
printf "---------------------------------------------\n"
}
#运行中
{
math+=$3
english+=$4
computer+=$5
printf "%-6s %-6s %4d %8d %8d %8d\n", $1, $2, $3,$4,$5, $3+$4+$5
}
#运行后
END {
printf "---------------------------------------------\n"
printf " TOTAL:%10d %8d %8d \n", math, english, computer
printf "AVERAGE:%10.2f %8.2f %8.2f\n", math/NR, english/NR, computer/NR
}
java 虚拟机相关
概述
关于java虚拟机,学过好几遍,但学一遍忘一遍。而我这个人,经常被人说“记忆力”好,比如我喜欢看电视剧,台词都记得。其实并不是我记忆力有多么的好,而是经常重复。前几天忽然想明白,我是如何记住那些电视剧台词的。首先要有兴趣记,兴趣这个事儿吧,是可以有的。只要你愿意对一件事培养兴趣,是能产生兴趣的,关键是你不愿意。而工作技能知识的学习,是需要有兴趣的,要有探索新知识的能力。再就是重复,重复次数多了,自然就能记住,比如快排算法,每天看一遍,默写一遍,总是能记住的。最后我能想到的一点是,把你想记住的内容,与你已经产生浓厚兴趣的其他事情建立联系。知识联系起来,就容易记住了。
虚拟机一些参数
# 设置堆内存,最小内存Xms,最大内存 Xmx。最大最小一样,可以避免堆自动扩展
-Xmx4g -Xms4g
# 设置方法区大小
-XX:PermSize=10m -XX:MaxPermSize=10m
对象是否存活
虚拟机判断可以回收已经不被使用的对象,书上介绍了两种判断方法。
- 引用计数法
有引用时,计数器加1;引用失效,计数器减1。优点是实现简单,判定效率高。问题是:无法解决循环引用的问题。 - 可达性分析(Reachability Analysis)
基本思想是以可以作为GC Roots的对象作为起点,向下搜索,搜索路径成为引用链(Reference Chain)。当一个对象不被任何一个GC Roots对象引用,就可以被回收。
可以作为GC Roots的对象有如下几种情况:
- 虚拟机栈中引用的对象
- 方法区中 类静态属性引用的对象
- 方法区中常量引用的对象
- 本地方法栈中JNI(Native方法)引用的对象
四种引用类型,由强到弱依次是:
- 强引用( Strong Reference )
普遍存在的类似于Object obj = new Object()就是强引用 - 软引用( Soft Reference)
描述一下有用 但非必须的对象。在系统将要发生内存溢出之前,会把这些对象列入回收范围内,进行第二次回收。 - 弱引用( Week Reference )
也是描述非必须的对象,这些对象只能生存到下一次垃圾回收之前。 - 虚引用( Phantom Reference )
一个对象是否有虚引用存在,不影响生存时间。也无法通过虚引用获取一个对象实例。设置虚引用的目的是:在这个对象被回收的时候,收到一个系统通知
对象实例回收过程:
一个对象被回收要经历两次标记过程:一是经过可达性分析后,没有与GC Roots相关的引用,这时,对象会被第一次标记,并判断是否需要筛选(执行其finalize方法);二是再次标记,则会被回收。如果第二次标记时,对象被重新引用,则可以逃过被回收。
类的回收:
当一个类被判断为无用类时,可以被回收。判断条件比较苛刻,必须同时满足三个条件。一是该类所有实例对象已经被回收;二是加载改类的ClassLoader被回收;三是该类的java.lang.Class对象没有在任何地方被引用,无法通过反射访问该方法。